Threaded Rendering GL Sample
Description
This sample demonstrates how to use threading to render efficiently in extended OpenGL.
APIs Used
- OpenGL ES 3.1AEP
Shared User Interface
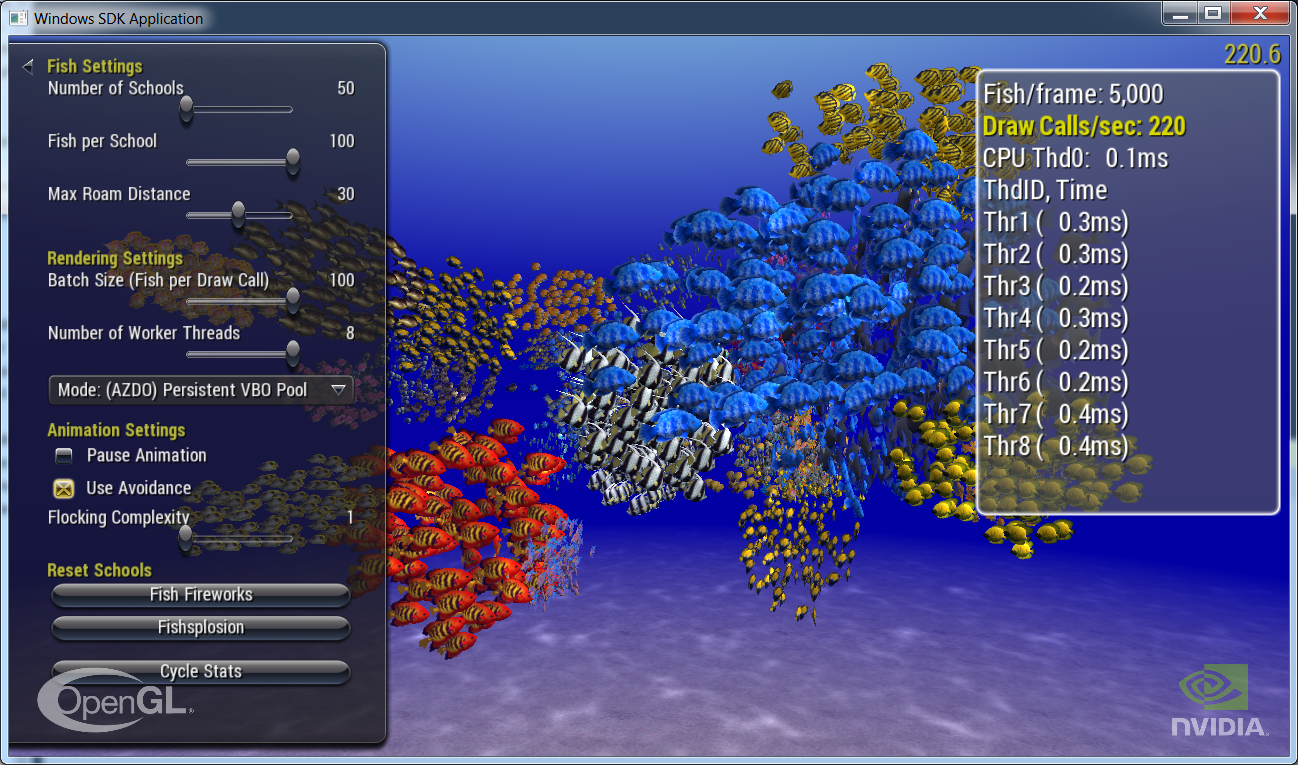
The Graphics samples all share a common app framework and certain user interface elements, centered around the "Tweakbar" panel on the left side of the screen which lets you interactively control certain variables in each sample.
To show and hide the Tweakbar, simply click or touch the triangular button positioned in the top-left of the view.
Technical Details
ThreadedRenderingGL
This sample renders thousands of swimming fish, of several varieties, flocking together in schools. In order to efficiently render such a large number of meshes, it implements several different techniques to reduce drawing overhead, as well as offload work to multiple threads.
Overview
Each school has a single fish mesh and renders a user-selectable number of instances of that mesh. The school maintains a flocking simulation for all of its fish that is updated every frame. The work of updating the flocking simulation is performed on a thread and is isolated such that each school may be updated simultaneously on separate threads with no synchronization between them. The user is able to change the number of threads used at runtime to see how the number of threads affects the performance of the sample.
The sample implements several different methods of managing the Vertex Buffer Objects (VBOs) used for rendering. Each of these methods has their benefits/drawbacks and some allow more of the preparation for rendering to be done in the schools' update thread, reducing the workload on the main thread.
Additionally, the sample implements several techniques to reduce driver overhead related to draw calls. These techniques are collectively referred to as "Approaching Zero Driver Overhead" or AZDO.
Vertex Buffer Management
This sample utilizes "hardware instancing" to render each school's fish. Using this method, there is one VBO that contains the vertices for the actual mesh object and a second VBO that contains an array of per-fish "instance" data. This instance data must be updated each frame for each fish. This sample uses three primary methods of managing the VBOs used to hold this instance data for the schools and their fish.- VBO Orphaning
- New storage space is requested for the VBO each frame and the previous frame's storage is "orphaned", allowing GL to reclaim it after it has finished using it to render. This is the simplest technique to implement and requires no synchronization, but is the least efficient.
- Mapped Sub Ranges
- A VBO is reserved with a size equal to the required size of the instance data multiplied by a number of frames. The VBO is then treated like a ring buffer and a sub-range of the VBO is mapped each frame to be used as the instance data VBO for that frame. Once each sub-range has been used, sub-ranges will need to be re-used and each subsequent frame must wait for any rendering that uses its associated sub-range to complete before it can begin filling in the instance data for the new frame.
- Pooled
- A large VBO is created from which each school receives a sub-range to treat as its instance data VBO. This entire VBO can be mapped once at the beginning of the frame and unmapped after all schools have completed their updating of their instance data. This greatly reduces the number of mappings (and the associated overhead) required each frame. Also, since the mapping occurs outside of the schools' threaded updates, they can directly update the instance data within their update, offloading that work from the main thread. Note that the large Pool VBO can, itself, use either the orphaning or mapped sub-range technique for its own strategy.
GLES vs. GL-AZDO
This sample supports rendering paths in both Open GLES 3 as well as Open GL with AZDO. All of the above techniques are applicable to both paths. In addition, the AZDO path takes advantage of the following techniques to reduce driver overhead- Persistent Mapped Buffers
- Normally you must Unmap a buffer that you have Mapped before you may use it to draw with. This feature allows a buffer to be used while it is still mapped, meaning that we can Map it once when it is created, update it and render with it each frame, and the Unmap it when we are completely finished with it.
- This is a core feature of Open GL 4.4 and available through either the extensions ARB_buffer_storage and EXT_buffer_storage in prior versions.
- Bindless Textures
- This feature allows handles to textures to be passed to shaders directly without having to bind them to texture units. These texture handles may be stored directly in Uniform Buffer Objects, allowing shaders to directly sample from them and using different textures within a single draw call based on other criteria.
- Bindless Textures are available through the NV_bindless_texture and ARB_bindless_texture extensions.
- Multi Draw Indirect
- This technique allows you to replace multiple draw calls with a single draw call by combining multiple meshes' worth of vertices, indices and instance data into one buffer of each type. You then build up an array of structures that describe the draw commands to be executed using those buffers and submit the whole thing as a single draw call, greatly reducing the driver overhead.
- Multi Draw Indirect is available as a core feature of Open GL 4.3 and later, or through the ARB_multi_draw_indirect and EXT_multi_draw_indirect extensions in prior versions.